
자료구조
내가 저장하려는 데이터를 효율적으로 저장하고 관리하는 방법이 자료구조입니다.
어떻게 하면 적은 메모리를 사용해서 내 데이터를 저장하고 관리할수 있을까? 에 관한 것이며 적절한 자료구조의 선택은 실행 성능의 향상을 기대할 수 있게 됩니다.
자료구조를 선택하려면 자료구조에 대한 장점, 단점에 대해 알고 있어야 합니다.
자료구조는 순차적인 순서를 갖는 선형 자료구조 / 비선형 자료구조로 나눠집니다.
선형 자료 구조
1. 배열(선형리스트)
배열은 청크 형태로 연속적인 메모리가 할당되는 공간입니다, 배열은 덩어리로 할당되는 자료구조이며 연속적으로 할당되기 때문에 각각의 원소에 접근할땐 0부터 1씩 증가하는 인덱스로 접근합니다.
배열은 가장 큰 장점이 임의 접근(random access)입니다. 내가 배열의 특정 원소에 임의 접근해서 그 원소 값을 가져다 쓸 수도 있고 임의 값을 집어 넣을 수도 있습니다. (a[3] = 99를 주고 싶다면 바로 값을 줄 수 있습니다)
- 내가 원하는 원소에 바로 접근할 수 있다
배열의 단점은, 정렬되어 있는 데이터에서 어떤 데이터를 삭제하고 싶다면 그 데이터를 꺼내기 위해서 그 다음 모든 원소들이 한칸씩 앞으로 이동을 해줘야 합니다. 원소 하나를 삭제하기 위해 데이터의 이동 횟수가 너무 많아지는 오버헤드가 발생할 수 있습니다.
- 원소의 추가 삭제에 많은 이동이 필요하여 오버 헤드가 발생할 수 있다
- 이 단점을 보완하기 위해 리스트를 사용한다
- 최악의 경우 n번 데이터를 이동한다
| 1 | 2 | 3 | 4 | 5 |
| [0] | [1] | [2] | [3] | [4] |
2. 리스트(연결리스트)
리스트는 원소를 노드라고 부르며, 노드들은 따로따로 저장되어 있습니다.
연결 리스트에서는 헤드가 필요하며 노드의 주소를 저장하고 있습니다. 각각의 노드는
다음 노드의 주소를 저장하고 있는 포인터를 가지고 있습니다.
연결리스트에서는 포인터 변수가 하나 더 필요하기 때문에 그만큼 공간이 더 필요하게 됩니다.
- 메모리를 더 많이 사용한다는 단점이 있다.
- 임의 접근이 불가하다
- 삽입과 삭제가 손쉽다는 장점이 있다
- 추가, 삭제가 빈번하다면 리스트를 그게 아니라면 배열을 이용하는 것이 좋다
- 추가로 이중 연결 리스트, 원형 리스트가 있다
배열에서 가장 큰 단점은 삽입에서 삭제할 때 데이터 이동이 힘들다는 것이며, 단점을 보완하기 위해 생겨난 것이 연결리스트입니다.

- 20번지에는 HYE가 있고, 40번지를 가리킵니다
- 40번지에는 YOUNG이 있고, 아무것도 가리키지 않습니다.
- 70번지에는 MOON이 있고, 20번지를 가리킵니다.
링크는 포인터이고 데이터를 연속된 기억공간에 저장하는 것이 아닌 아무데나 저장이 가능하고 다음 노드만 잘 연결시켜주면 됩니다. 다음 노드를 가리키는 링크 정보를 가지는 것이 연결 리스트가 되는 것이고 연결 구조로 되어있는 하나하나를 노드라고 이야기합니다. 다음에 연결되는 노드를 가리키는 포인터, 링크라는 필드로 구성이 되어 있습니다.
연결리스트 최대 장점은 삽입, 삭제가 편리하다는 것입니다, 주소가 100번지인 데이터 BB를 삽입을 하고 싶다면, AA가 40을 가리키고 있었다면 지우고 100을 가리키게 합니다.

20번지의 BB를 지우고 싶다면 AA를 20번지를 가리키고 있던 것을 40번지로 바꿔줍니다

연결리스트는 희소 행렬을 표현할 때 기억장소 이용 효율이 좋습니다
(희소행렬 : 유효한 숫자보다 0이 훨씬 많은 행렬)
포인터로 찾아가기 때문에 데이터를 찾아가는 속도는 느리고 포인터를 위한 추가 공간이 필요합니다. 공간을 분할해서 주소, 데이터, 포인터로 나눈 것입니다. 그리고 어쩌다가 중간에 가리키는 포인터(화살펴)가 사라지면 그 뒤로부터는 우수수 데이터를 찾을 수 없게 됩니다.
- 원형 연결리스트 : 맨 끝에 있는 노드가 맨 앞의 노드를 가리키기 때문에 사이클 형식으로, 원형으로 되어있기 때문에 어디서 시작하든지 모든 노드를 가리킬 수 있습니다. 만약 내가 찾는 노드가 없으면 무한루프에 빠질 수 있는 단점이 있습니다
- 이중 연결리스트 : 양방향으로 탐색이 가능하도록 두개의 링크필드(포인터)를 갖습니다. 포인터가 하나 고장나도 다른 포인터가 있기 때문에 복구가 가능하지만 데이터를 저장할 공간(기억공간)은 더 줄어듭니다. 그래서 기억공간의 낭비가 발생합니다
- 이중 원형 연결 리스트 : 양방향인데 맨 끝의 노드가 맨 앞의 노드를 가리키는 구조
3. 스택
스택이란 한쪽 방향으로 삽입과 삭제가 이루어지는 자료구조입니다.
삽입하는 작업이 PUSH 이고 삭제가 POP입니다. 데이터 1,2,3을 저장하면 1,2,3 순서대로 차곡차곡 쌓입니다.
삭제를 할 때는 가장 마지막에 들어온 데이터가 먼저 빠집니다 (3,2,1 순서대로) ==> LIFO 방식
예를 들어 인터넷 뒤로가기가 있습니다.
*스택은 자료구조가 따로 있는데 아니라 배열이나 리스트로 구현을 합니다. 들어온 순서대로 나올 수 있는
배열이 구현하기 가장 좋습니다
스택은 인터럽트 복귀 주소, 산술식 표현, 함수 호출에 사용됩니다
만약 A B C가 들어와서 크기가 찼는데 데이터 D가 들어오려고 하면 못 들어옵니다. 본인이 받아들일 수 있는 만큼만 데이터를 받아야 하고 아니면 넘쳐서 오버플로우가 일어납니다.
처음 크기가 주어졌을 것이고, 그래서 데이터가 들어올 때마다 그 위치를 알려줘야 합니다 (오버플로우 확인)
그게 TOP이라는 포인터입니다.
데이터를 TOP=1로 먼저 만들고나서 데이터 A를 받아들이고, 다시 TOP=2로 만들고 B를 받아들이고....
크기가 3인데 TOP=4가 되면 더이상 데이터가 못들어갑니다.
*위치를 나타내는 것이 TOP, 맨 밑을 가리키는 것이 BOTTOM 입니다.
스택의 크기를 벗어나는 오버플로우가 있고 더이상 삭제할게 없는데 삭제하려고 하면 언더플로우가 발생합니다.
삽입 알고리즘
if(TOP>N) then overflow; //참이면 수행
else { //거짓이면 수행
data ← stack(top); //데이터 삽입
top = top+1; //top 증가
}- TOP = 0
- TOP = 1, A 삽입
- TOP = 2, B 삽입
- TOP = 3, C 삽입
- TOP = 4, D 삽입
삭제 알고리즘
if(TOP=0) then underflow; //참이면 수행
else { //거짓이면 수행
data ← stack(top); //데이터 삭제
top = top-1; //top 감소
}
스택을 이용한 수식 연산
연산자를 어디에 배치하냐에 따라 달라집니다
- 전위식(prefix) 연 데 데
- 중위식(infix) 데 연 데
- 후위식(postfix) 데 데 연

후위 형식은 데이터 데이터 연산자 방식입니다.
스택은 연산자를 만나면 데이터 두개를 꺼내서 연산하고 다시 넣습니다.
| 3 | ||||||
| 5 | 2 | 2 | 6 | |||
| 4 | 4 | 9 | 9 | 9 | 9 | 3 |
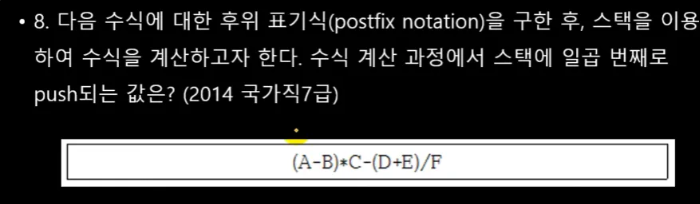
후위 표기법으로 바꾸면, 연산자 우선순위로 괄호하고 오른쪽으로 꺼내주면 됩니다.
(((A-B)C)-((D+E)/F)) ⇒ AB-CDE+F/-
스택에 넣으면
| B | C | D | |||
| A | A | A-B | A-B | (A-B)*C | (A-B)*C |
| E | F | |||
| D | D+E | D+E | D+E/F | |
| (A-B)*C | (A-B)*C | (A-B)*C | (A-B)*C | (D+E)/F-(A-B)*C |
4. 큐
큐는 양쪽이 뻥 뚫린 구조가 되고, 뒤쪽으로는 삽입만, 앞쪽으로는 삭제 작업만 이루어집니다
(예: 버스 앞문으로는 타고 뒷문으로는 내리기만 하는 구조)
- 삽입되는 곳 : rear (뒤)
- 삭제되는 곳: front (앞)
내가 A,B,C 순서대로 넣으면 A,B,C 순서대로 나가는 구조입니다 —> FIFO 구조, LILO 구조
작업 스케줄링이나 버퍼 관리에서 사용됩니다

- 삽입 알고리즘
rear를 하나 증가시키고 삽입 과정이 이루어지는 것을 반복하는데 큐에 들어갈 수 있는 한계가 있습니다.
rear = n 이면 포화 상태라고 말합니다.
아니라면 rear를 하나 증가시키고 새로운 데이터를 넣습니다.
- 삭제 알고리즘
A,B,C가 있고 A가 front=1이면 B는 front=2 입니다.
만약 front=rear이면 큐가 비어있는 것입니다. 이때는 삭제 연산을 할 수 없습니다.
아니라면 front를 하나 증가시키고 데이터를 삭제합니다
원형큐
선형큐의 앞과 끝을 연결시킨 구조입니다. 선형 큐의 문제점은 데이터 공간이 다 차면 많은 이동이 일어나야 합니다. 그 문제점을 해결하기 위해 원형큐가 있습니다. (데이터를 이동할 필요가 없음)
- 아무 데이터가 삽입되지 않음 : r=0, f=0
- 데이터가 삽입될 때마다 r + 1
- 언더플로우, 오버플로우 구분이 X
- 나머지 연산자를 사용한다. 6개의 데이터의 6번 데이터라면 6/6을 해서 나머지는 0이 되는 것
- 0번부터 출발했기 때문에 마지막은 N-1번이다

5. 데크(dequeue)
양쪽 방향에서 삽입과 삭제가 모두 이루어집니다
- 스크롤 : 입력 제한
- shelf : 출력 제한
https://www.youtube.com/watch?v=_4DceTNQfro&list=PLt6CKTxU611Oz9x68XyrdXfsnedNCnXRJ&index=53 강의를 참고하여 포스팅 하였습니다
'컴퓨터 일반 > 자료구조론' 카테고리의 다른 글
| 자료구조 문제 정리 (1) 배열, 리스트 (4) | 2024.10.25 |
|---|---|
| 알고리즘 시간복잡도 (0) | 2024.10.24 |
| 자료구조 트리 (3) | 2024.10.23 |
| 그래프 알고리즘 (1) | 2024.10.23 |
| 자료구조 그래프 정리 (1) | 2024.10.23 |


