데이터 모델링의 순서인
업무 파악 -> 개념적 데이터 모델링 -> 논리적 데이터 모델링 -> 물리적 데이터 모델링
중, 논리적 데이터 모델링에 대해 알아보자.
논리적 데이터 모델링이란?
개념적 데이터 모델링에서 뽑아낸 개념을 관계형 데이터베이스에 어울리도록
데이터 형식을 잘 정리정돈 하는 것이다. Mapping rule을 사용할 수 있다.
Mapping Rule은 ER 다이어그램을 통해 표현한 내용을 관계형 데이터베이스에 맞는 형식으로 전환할 때 사용할 수 있는 방법론이다.

이런 식으로 그려보는 것!
Entity는 Table로, Attribute는 Column으로, Relation은 PK,FK로 전환하면 된다.
테이블에 컬럼을 추가할 때 해당 컬럼에 들어가는 속성의 여러가지 제약조건(데이터의 형식, 길이, primary key 지정 유무 등등..)을 그 컬럼의 도메인을 설정한다고 한다.
Relation을 PK, FK로 연결하기
개념적 데이터 모델링에서 알아본 엔티티 간의 관계를 나타내는 것이다.
여기서 가장 중요한 부분은 Cardinality이다.
1. 1:1 관계 처리하기
회원 테이블이 있고, 휴면회원 테이블이 있다.
회원 아이디와 휴면회원의 아이디가 같다면
누가 foreign key를 가질까?
회원은 휴면회원의 id 값과 상관 없이 값을 추가할 수 있다.
휴면회원은 회원의 id 값이 있는 것만을 추가할 수 있다.
휴면회원은 회원이 누구인지 알아야하고, 회원은 휴면회원이 누구인지 몰라도 된다.
즉, 휴면회원은 회원에게 의존하고 있다.
- 혼자서도 잘 지낼수 있는 회원은 부모 테이블, 혼자서는 잘 지낼수 없는 휴면회원은 자식 테이블이다.
- 독립적인 회원 테이블이 parent이고, 의존적인 휴면회원 테이블이 child 이다.
- 회원 테이블이 primary key, 휴면회원 테이블이 foreign key이다.
- 휴면회원 테이블에게 회원 테이블은 반드시 있어야 한다. 0...1 이다.
- 회원에게 휴면회원은 반드시 있지 않아도 된다. 1이다.
2. 1:N 관계 처리하기
댓글과 글, 저자와 댓글의 관계이다.
저자는 댓글을 가질수도, 갖지 않을 수도 있고 저자 한명은 여러 개의 댓글을 가질 수 있다.
댓글은 저자와 글 모두와 관계를 갖는다.
comment(댓글)이 만들어지려면 author와 topic의 정보가 필요하다. topic_id와 author_id는 foreign key가 된다.

topic에게 comment는 옵션이다. 0..n 관계이다. comment에게 topic은 1이다.
author에게 comment는 옵션이다. 0..n관계이다. comment에게 author는 1이다.
3. N:M 관계 처리하기
한 명의 저자는 여러 개의 글을 쓸 수 있고, 하나의 글을 여러 명의 저자가 작성하고 편집할 수 있다.
즉, 저자 테이블과 글 테이블은 N:M 관계이다.
아이디가 1인 kim이라는 저자가 MySQL, SQL server, ORACLE 글을 작성했고
아이디가 2인 lee라는 저자가 MySQL, SQL server 글을 작성했다면

이렇게 행의 값을 2개 가지게 된다. (에러)
이런 경우 author도 topic도 아닌 중재자가 필요한데 이를 매핑테이블(연결 테이블)이라고 부른다.
write라는 매핑 테이블을 만들어보자.

이 테이블에는 author_id와 topic_id를 적는다. write 테이블은 author_id와 topic_id를 foreign key로 가지게 된다.
id가 1인 kim은 topic "MySQL, SQL server, ORACLE"을 작성했고
id가 2인 lee는 topic "MySQL, SQL server"를 작성했다는 것을 나타낼수 있다.
이러한 매핑 테이블의 또 다른 장점은 두개의 테이블이 결합되었을 때 의미가 있는 정보도 추가할 수 있게 된다는 것이다. (예: 각각의 저자가 글을 수정한 시간 등)
Normalization(정규화)
관계형 모델의 발견자인 에드거 F. 커드는 1970년부터 정규화 개념을 도입하였다.
정규화란 정제되지 않은 데이터 표를 관계형 데이터베이스에 어울리는 표로 만들어주는 레시피이다.
평범한 사람도 이 방법을 적용하면 탁월한 표를 만들 수가 있다.
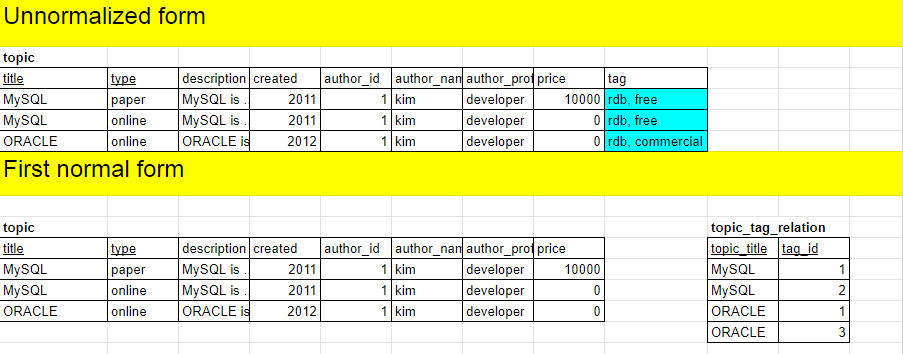
여기에 하나의 표가 있다. 정규화가 되어있지 않은 Unnormalized form 이다.

- 두 개의 primary key를 가지고 있다.
- 중복되는 값이 있다.
- 하나의 컬럼에 여러 개의 값을 가지고 있다.
즉, 관계형 데이터베이스에 어울리지 않는 표이다.
1. 제 1정규형을 만드는 제 1정규화
Atomic columns
각 행, 컬럼의 값들이 원자적이여야 한다.
제 1형 정규형의 원칙은 각각의 컬럼의 값들이 값을 하나만 가져야 하는 것이다.
Unnormalized form의 tag는(하늘색) 값을 두가지 가지고 있다.
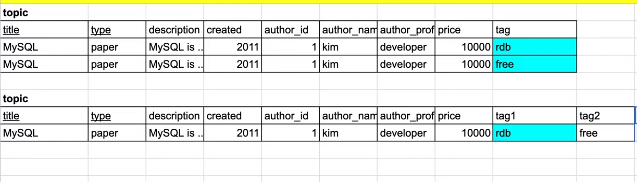
위의 방법은 제 1형의 정규형의 원칙을 만족하나 값의 중복이 발생하고
아래의 방법은 테이블의 구조를 바꿔야하며, 해당 컬럼에 값이 없을 경우 null 값을 넣어 낭비가 생긴다.
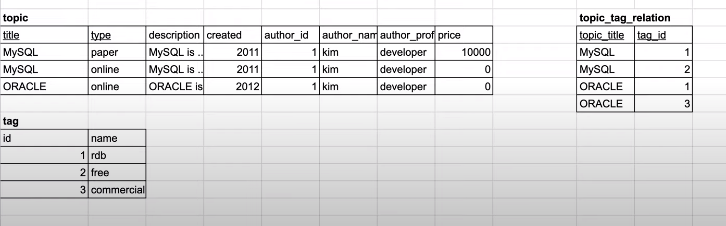
하나의 topic은 여러 개의 tag를 가질 수 있고, 하나의 tag는 여러 개의 topic을 가질 수 있다.
즉, N:M 관계를 가지므로 매핑 테이블을 topic_tag_relation 만든다.
또한 topic은 title과 type을 primary key로 가지고 있지만 tag는 글의 제목인 title에만 의존하고 있다.
따라서 매핑 테이블 topic_tag_relation을 만들땐 title과 tag_id를 가져와서 primary key로 만든다
2. 제 2정규형을 만드는 제 2정규화
No partial dependencies
부분 종속성이 없어야 한다는 조건을 만족해야 한다(=표의 기본키 중 중복키 인것이 없어야 한다)
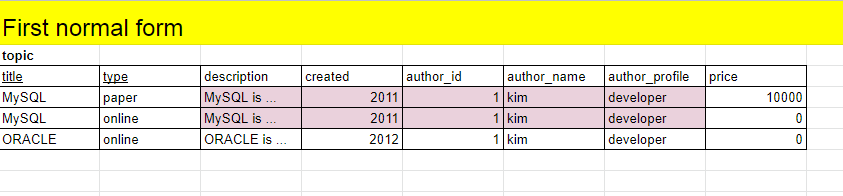
위의 표를 보면 색칠된 부분에서 중복이 발생하고 있다.
중복이 발생하는 이유는 부분 종속성 때문인데, 색칠된 행은 MySQL이라는 제목(title) 하나에만 의존하고 있기 때문이다.
primary key는 title과 type이지만 title에 종속되어 있고, type과는 관계가 없다 => 부분 종속성
topic 테이블의 존재 의의는 price 때문이다.
<해결 방법>
부분적으로 종속되는 컬럼들(description, created, author_id, author_name, author_profile)만 모아서 title만 primary eky로 주는 테이블로,
전체적으로 종속되는 컬럼(price)를 따로 쪼개서 primary key를 title, type으로 주는 topic_type 테이블을 만든다.

3. 제 3정규형을 만드는 제 3정규화
No transitive dependencies
이행적 종속성이 없도록 한다.
이행적 종속성이란?
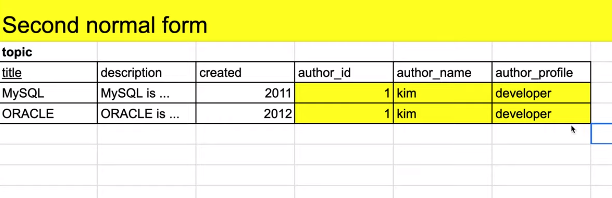
행은 title이라는 기본키에 종속되어 있다.
author_id는 title에 의존하고 있으나, author_name, author_profile은 author_id에 의존하고 있다.
이러한 관계를 이행적 종속성이라고 하며, 이런 경우 중복이 발생한다.
중복을 만드는 부분 author_name과 author_profile을 따로 빼서 새로운 테이블인 author를 만들면 중복을 제거할 수 있다.
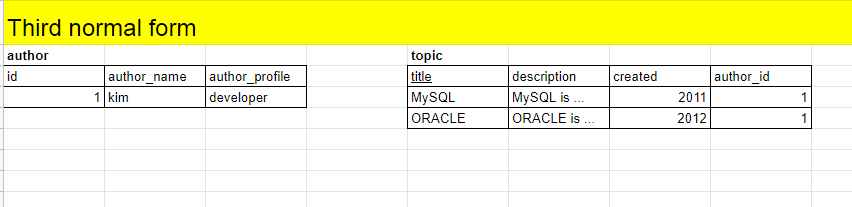
여기서 topic 테이블의 author_id는 foreign key이기 때문에 중복을 제거하지 않는다.
해당 게시글은 '생활코딩' 님의 관계형 데이터 모델링 강의를 참고하였습니다.
출처 https://www.youtube.com/watch?v=aS9FoCNlt3o&list=PLuHgQVnccGMDF6rHsY9qMuJMd295Yk4sa&index=25
'DATABASE' 카테고리의 다른 글
| MySQL (1) - 테이블 생성, CRUD, JOIN (0) | 2021.12.12 |
|---|---|
| 관계형 데이터 모델링(3) - 물리적 데이터 모델링 (0) | 2021.12.11 |
| 관계형 데이터 모델링(1) - 개념적 데이터 모델링 (0) | 2021.12.10 |
| SQL JOIN - LEFT OUTER JOIN, INNER JOIN (0) | 2021.12.10 |
| ORACLE DATABASE - PRIMARY KEY, SEQUENCE (0) | 2021.12.09 |



